Что случилось с Cloudflare 18.11.2025
Все началось с рутинного обновления прав доступа в кластере ClickHouse.

Пробема #1
Они не меняли выборку и условия, они поменяли настройки прав. И запрос, который раньше возвращал данные только от одной БД, стал возвращать от нескольких БД (из основной базы и из внутреннего шарда r0).
То есть, раньше все нормально работало и без условия, а после изменения настроек прав - тот же самый запрос, который раньше нормально работал, стал выдавать дубликаты данных, что привело к проблемам.

Проблема #2
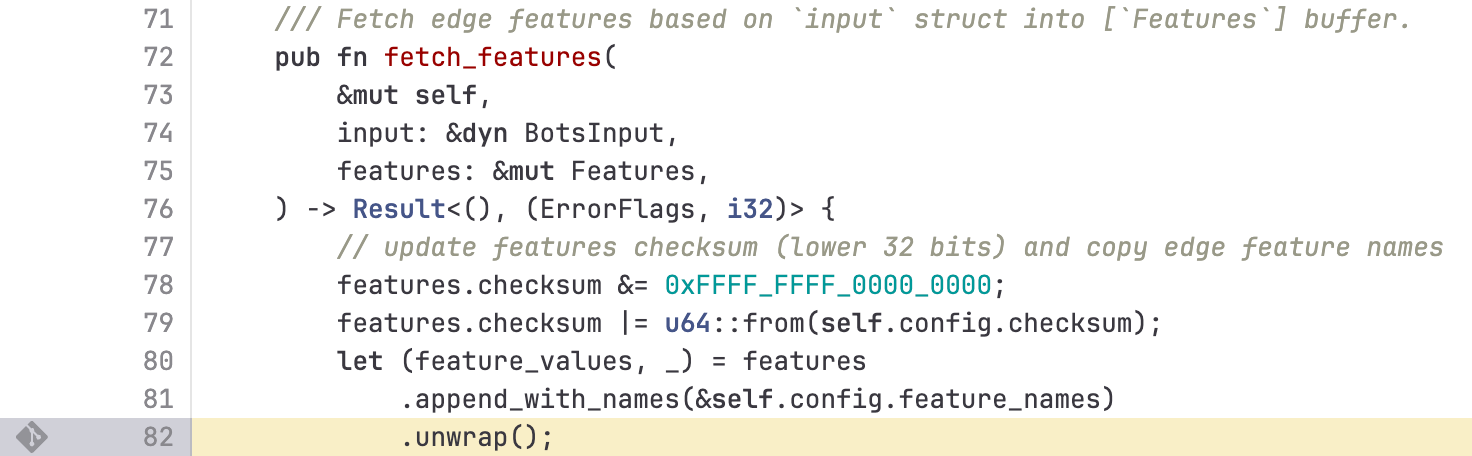
В коде прокси-сервера (написанном на Rust) стояло ограничение на 200 входных параметров, под которые заранее аллоцировалась память, видимо разработчики наивно полагали, что больше им никогда не понадобится. 640 килобайт хватит всем.
Вместо корректной обработки превышения и использования старой версии файла с уведомлением мониторинга, обработчик аварийно завершал работу из-за использования в Rust метода unwrap() для Result в состоянии Ok. При ошибке unwrap() вызывает panic!, что допустимо в отладке, но недопустимо в продакшене.
Проблема #3
Чинили это дело в лучших традициях… вручную остановили раскатку обновления, подсунули старый (рабочий) файл конфигурации и начали перезагружать всю глобальную инфраструктуру. Полностью разгрести завалы и очереди сообщений удалось только к вечеру.

Длинная и скучная официальная версия в блоге cloudflare
tags: cloudflare - incident